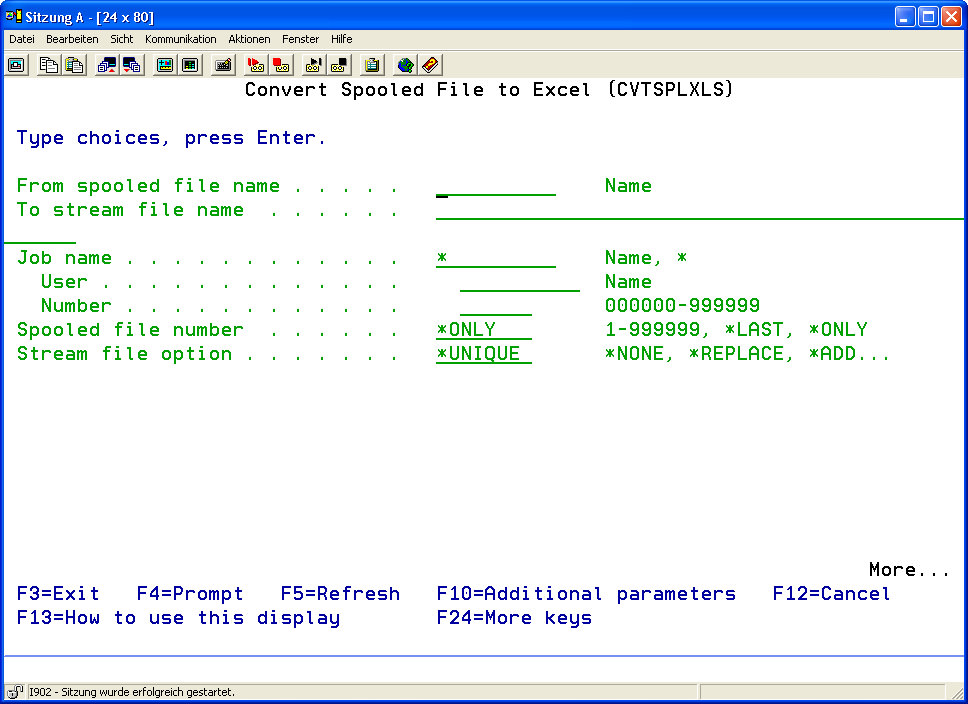
| Spooled File (FILE) | The description of this parameter can be found underMenu item 11: Convert spool file to PDF (CVTSPLPDF) Part 1 |
| OUTPFILE | The description of this parameter can be found underMenu item 11: Convert spool file to PDF (CVTSPLPDF) Part 1 |
| JOBNAM | The description of this parameter can be found underMenu item 11: Convert spool file to PDF (CVTSPLPDF) Part 1 |
| SPLNBR | The description of this parameter can be found underMenu item 11: Convert spool file to PDF (CVTSPLPDF) Part 1 |
| STMFOPT | The description of this parameter can be found underMenu item 11: Convert spool file to PDF (CVTSPLPDF) Part 1 |
| EXCEL | This parameter determines a number of Excel file related options.This parameter contains 27 elements: | Excel File Format Version | | *BIFF8 | BIFF 8 is the Excel file format used by Excel 97 and supported by later versions of Excel. This will normally be the file format created, unless a ver-sion of Excel earlier than Excel 97 is in used. | | *BIFF5 | A BIFF 5 file will be created. Use this file format only if Excel Versions 5 or 7 are used. |
| | Use Page Headings? | This option determines the way lines will be handled, which are recognized as headings. After analysing a sample of the spooled file's data, i-effect will decide which lines are report data content and which are not. Any lines which precede the first report data line, but which do not appear to be a column heading, will be considered a page heading. This element then determines how such lines are handled. | *FIRST | The first occurrence of a unique page heading line is retained, but all subsequent occurrences of that line will be excluded from the output. Note: Any variation in the page heading from one page to the next (such as a change in the time that is printed at the top of the page) may cause i-effect to retain a heading which should be excluded. The EXCLLINNBR or EXCLLINKEY parameters can be used to exclude unwanted headings, which i-effect did not exclude. | | *ALL | All headings will be converted. | | *NONE | No headings will be converted. |
| | Use Column Headings? | Following statistical analysis of a sample of the data in the spooled file, i-effect will decide which lines are report data content and which are not. Any lines which immediately precede the first report data line, and which overlap the data columns in the report, will be considered column headings. This element then determines how such lines are handled. | *FIRST | The first occurrence of a unique column heading line is retained, but all subsequent occurrences of that line are excluded from the output. Note: Any variation in the column heading from one page to the next may cause i-effect to retain a heading that should be excluded. The EXCLLINNBR or EXCLLINKEY parameters can be used to exclude unwanted headings, which i-effect did not exclude. | | *ALL | All column headings will be converted. | | *NONE | No column headings will be converted. |
| | Spooled File's Currency Symbol | This element determines the currency symbol that appears when printing currency values in the report. It is important that i-effect knows which currency symbol is to be used in the report, so that it can correctly identify columns of numbers that include a currency symbol as numerical data rather than treating them as text. | *SYSVAL | The currency symbol defined by the QCURSYM system value is used in the report. | | Currency Symbol | Specify the currency symbol, which will be used in the report, if this is different from the system currency symbol. For example, if processing a report containing values in dollars on a system where the currency symbol is a pound sign (£), specify $. i-effect will interpret data containing dollar signs as numerical data not text. |
| | Decimal Separator of the Spooled file | This element determines the decimal separator that is used when printing numbers in the report. It is important that i-effect knows which decimal separator is used in the report so that it can correctly identify columns of numbers as numerical data rather than treating them as text. | *JOB | The decimal separator defined by the DECFMT attribute of the current job is used in the report. | | *SYSVAL | The decimal separator defined by the QDECFMT system value is used in the report. | | Decimal Separator | Specify the decimal separator, which will be used in the report. For example, if processing a report containing numbers that have a period as the decimal separator on a system where the normal thousands separator character is a comma (,), specify period (.). i-effect will interpret periods in numerical data as a decimal separator, not a thousands separator. |
| | Spooled file's Thousands Separator | This element determines the thousands separator that is used when printing numbers in the report. It is important that i-effect knows which thousands separator is used in the report so that it can correctly identify columns of numbers as numerical data rather than treating them as text. | *JOB | The thousands separator determined by the DECFMT attribute of the current job is used in the report. | | *SYSVAL | The thousands separator determined by the QDECFMT system value is used in the report. | | Thousands Separator | Specify the thousands separator which will be used in the report. For example, if processing a report containing numbers that have a period as the thousands separator on a system where the normal thousands separator character is a comma (,), specify period (.). i-effect will interpret periods in numerical data as a thousands separator, not a decimal point. |
| | Date Format of the Spooled file | This element determines the report's date format. | *JOB | The report's date format is determined by the current job's DATFMT attribute. | | *SYSVAL | The report's date format is determined by the QDATFMT system value. | | *DMY | The report's date format will be day-month-year. i-effect will identify data in the report, which looks like a valid DMY date, as a date (2-digit or 4-digit year). | | *MDY | The report's date format will be month-day-year. i-effect will identify data in the report, which looks like a valid MDY date, as a date (2-digit or 4-digit year). | | *YMD | The report's date format will be year-month-day. i-effect will identify data in the report, which looks like a valid YMD date, as a date (2-digit or 4-digit year). |
| | Spooled File's Date Separator | This element determines the date separator that is used for printing dates in the report. It is important that i-effect knows which date separator is used in the report so that it can correctly identify dates and treat them as such. | *JOB | The report's date separator is determined by the DATFMT attribute of the current job. | | *SYSVAL | The report's date separator is determined by the QDATFMT system value. | | Date Separator | Specify the report's date separator character. For example, if processing a report containing dates that have a hyphen as date separator on a sys-tem where the normal date separator character is a slash then specify hyphen (-). |
| | Word used for "Page" in the Spooled File. | This element defines the word "Page" as it appears in the report.When excluding page headings, i-effect attempts to take account of lines differing only by a change of page number. To do so, i-effect looks for the word defined with this element followed by a number, treating that text as a page number and ignoring it when deciding whether a page heading is a new one or a repetition of a previous one. | *DFT | The word for "Page" is taken from the text of message CVT0008 in message file CS_MSGF. In the English-language version of i-effect the word is "Page". Please note: If the text in this message file has been changed, it must be changed again when applying PTFs or new versions. | | Character Value | Specify the word for "Page" which is used with page numbers in the report. For example, if it is abbreviated to "P" specify P here. Similarly, if processing a Spanish-language report, "Página" may be appropriate. |
| | Excel Date Format | The format, which will be applied to dates in Excel spreadsheet. Using the information specified above concerning the report's date format and date separators, i-effect will attempt to identify data items in the report, which are dates. These will be rendered as standard Excel dates (a day count since the start date) in numerical cells, but the appropriate date format, which was specified here, will be applied. | *MM | A two-digit numeric month will be used, e.g. 01= January. The date format will otherwise be determined by the Excel settings and the regional settings of the PC. | | *MMM | A three-character month will be used, e.g. Jan = January. The date format will otherwise be determined by the Excel settings and the regional settings of the PC. |
| Excel Worksheet Name | Name of the worksheet. If the name ends in a number (e.g. "Sheet1") i-effect will generate names for subsequent worksheets incrementally (e.g. "Sheet2", "Sheet3"). If the specified name does not end in a number, i-effect will generate the names of subsequent worksheets by adding a numerical suffix (e.g. if the sheet name specified is "Invoices", the next sheet will be „Invoices2" etc.). | *DFT | The worksheet name is taken from the text of message CVT0021 in message file CS_MSGF. In the English-language version of i-effect the name is "Sheet1". Please note: If the text in this message file has been changed, it must be changed again when applying PTFs or new versions. | | Worksheet Name | Specify the name of the worksheet that i-effect should create. |
| Title | The text entered here will appear under "Title" in the Excel file properties. | *NONE | The file has no title. | | The file's Title | The title of the Excel file. |
| | Subject | The text here will appear under "subject" in the Excel file properties. | *NONE | The file has no subject. | | Subject of the Excel File | Up to 32 characters of subject text are allowed. |
| | Author | The text here will appear under "Author's Name" in the Excel file properties. | *NONE | The file has no author. | | *USRPRF | The author's name will be taken from the user profile. | | *JOB | The author's name will be take from the job name e.g. FAKTURAJOB. | | *QUALJOB | The author's name will be the full qualified job name e.g. 123456/VERKAUF/FAKTURAJOB. | | Author's Name | Up to 32 Characters can be entered as the author's name. |
| | Last Saved by | The text entered here appears in the file properties as "Last saved by." | *NONE | The file has not been changed. | | Entry | Up to 32 characters of text are possible. |
| | Company | The text here will appear as "Company Name" in the Excel file properties. | *NONE | The file has no company name. | | Company Name | Enter the company name, for which the file was created. |
| Keywords | The text here will appear under "Keywords" in the Excel file properties. | *NONE | No keywords are specified. | | Entry | Specify the keywords, which should be dis-played. |
| | Comments | The text here will appear under "Comments" in the Excel file properties. | *NONE | The file contains no comments. | | Entry | Up to 256 characters can be entered as commentary. |
| Category | The text hear will appear under "Category" in the Excel file properties. | *NONE | The file will not be assigned to a category. | | Entry | Up to 32 characters can be entered here as text. |
| | Page Breaks | This element determines if i-effect should insert page breaks in the Excel file at the end of each page in the original spooled file. | *NO | No page breaks will be inserted. | | *YES | A page break will be inserted in the Excel file after the last row of each page in the original spooled file. |
| | Remove Dot Leaders | Determines if i-effect should remove dot leaders from the output. Dot leaders (such as in ‚Customer number . . . . . : XXXXXX') are often used in reports to connect data items with their associated labels, but in Excel output they can make the document illegible, and can confuse the logic which determines where to place column breaks. | *NO | Dot leaders will not be removed. | | *YES | Dot leaders are removed (replaced with spaces). |
| Remove Underlining IKKTODO
| Determines if i-effect should remove consecutive underscores from the output. Underlining in the output (created using underscore characters "_") can enhance the appearance of the printed page; it tends to detract from the appearance of the data in an Excel file. i-effect can remove any consecutive underscores it finds. | *YES | Underscores will be removed. | | *NO | Underscores will not be removed. |
| | Column delimiters | If COLUMNOPT (* TOKEN) is specified, the value defined in this parameter, the way splits in the i-effect data in the print file in columns of file to be generated. The omission is * SPLF. This tells i-effect so divide the print data in columns, as the data is divided in the original report.
Where the print file from a compressed file externally described, this method will achieve all probability the best results, because the data are likely to be organized in the print file that naturally or logically related data as a separately identifiable elements appear. However, if the print file was generated from a print file internally described, or from an application such as Query / 400, then it is likely that the print data of i-effect as a single unstructured data block for each print line is seen in the report. If that's the case, better results will be obtained, in which a column separator is defined to control the division into columns of the report.
Every time i-effect n detected consecutively occurring sign of the defined in this parameter element type, he will begin a new column. n is the number that is defined for the next element. ( "Number of column separators").
For example, if you specify * BLANK in this element and 2 in the next item, i-effect will begin a new column when 2 or more spaces in the print file after another are found.
If i-effect acknowledges that the spool file was from a file without DDS, produced, or from a Query / 400 query, then it automatically becomes the equivalent of * BLANK for "column delimiter" and 2 for "number of column separator (See Next element) switch. | *SPLF | Share the data in the report based on the internal organization of the data in the file. | | *BLANK | The delimiter is a space. | | character value | Character to use as a column delimiter for column separations. |
| | Number of column separators | The number of column separator, the successively
must occur before a column separation. | *NONE | This method is not used. | | 1-9 | The number of required delimiter. |
| | Specifies whether columns unused are hidden or not. | *NO | Not used columns are not hidden. | | *YES | Not used columns are hidden. |
| | Hide rows Unused | Determines whether lines not used are hidden or not. | *NO | Non lines used are not hidden. | | *YES | Non lines used are hidden. |
| | Number of fixed lines | How many lines are to be fixed at the top? Frozen rows will not scroll with the rest of the worksheet and are typically used for page headers. | *NONE | There is no fixed rows | | 1-32767 | Specify the number of rows that are to be fixed. |
|
|
| Excel worksheet protection (XLSPROTECT) | Options for spreadsheet protection are specified here. | Protect Worksheet | | *NO | No protection options are specified. | | *YES | The worksheets will be protected from modification. |
| | Worksheet Protection Password | | *NONE | No password will be required to unprotect the worksheet. The user who opens the file will be able to unprotect the worksheet simply by selecting the appropriate menu option | | Character Value | Enter a password to protect the worksheet. |
| | Encrypted password Available | |
|
| Column Creation Options (COLUMNOPT) | This controls the way in which i-effect calculates columns, into which the data from the spooled file will be arranged in the Excel file.
This parameter contains 2 elements: | Column Determination Method | | *CALC | i-effect calculates column positions automatically. | | *POS | Specify the column positions manually, using the COLUMNPOS parameter. | | *CALCPOS | i-effect calculates the column positions automatically, but the user fine-tunes the selected column positions using options in the COLUMNPOS parameter. | | *TOKEN | i-effect will calculate the column positions automatically by identifying text "Tokens" in the spooled file. This is equivalent to the EXCEL(*OLD) method available from CVTSPLSTMF. | | *SPLF | |
| Column Generation Value | This option can influence the way in which i-effect's algorithm for calculating column position operates. The algorithm uses statistical techniques to identify character positions in the report where left-aligned alphanumerical or right-aligned numerical columns of data appear. The algorithm will select character positions where such items occur with a frequency that is more than a given number of standard deviations from the norm. The value specified here is the number of standard deviations to use. If the default value (1 standard deviation from the norm) does not give good results, it can be adjusted to a different value. | 0.00-9.99 | The number of standard deviations from the mean to be used by the column selection algorithm. |
|
|
| Excel Comlumn Position (COLUMNPOS) | This parameter specifies column positions, which will be used in the Excel file (in conjunction with COLUMNOPT(*POS)) or to override the column positions determined automatically by i-effect (in conjunction with COLUMNOPT(*CALCPOS).
Note: i-effect will send messages to the job log regarding the column positions selected. These messages can be helpful in identifying the column positions, which need to be modified, with the COLUMNPOS parameter.
Possible Values:
| *CALC | No column positions are defined. COLUMNOPT(*CALC) must be specified. | | Other Values | (Up to 100 are possible) |
This parameter contains 5 elements:
| Column Position in the Spooled File |
| 1-999 | The character position in the report where the column will be added or removed. |
| | Action to Take at this Position |
| *RMV | The column, which was created at the specified character position, will be removed. |
| | Left or Right Column: |
| *ADD | A column will be created at the character position specified in the report. |
| | Alpha. or numeric column? | | *LEFT | The column will be left-aligned. | | *RIGHT | The column will be right-aligned. | | *ALPHA | The column contains alphanumerical data (labels). | | *NUMERIC | The column contains numerical data. |
| | column width | | *CALC | The column width will be calculated using the position of the adjacent column. | | width | The column width in characters, measured from left to right for left-aligned columns and - from right to left for right-aligned columns. |
|
|
| Excel Columns (XLSCOLUMNS) | This parameter can fine-tune the decisions made by i-effect regarding allocation and format of data in columns in Excel spreadsheets .
Single Values: | *NONE | No column actions will be defined. | | Further Values | (Up to 100 repetitions) |
This parameter contains 2 elements: | Column ID |
| Entry | Specify the column's column letter to which the action is applied . |
| Column Action |
| *DROP | Deletes the column and it's data from the output. | | *MRGLFT | Data, which is contained in this column, will be merged to the column which is on its left. If this column contains data, the data will be merged together. | | *MRGRGT | Data, which is contained in this column, will be merged to the column which is on its right. If this column contains data, the data will be merged together. | | *ALNLFT | Aligns the colomn to the left. | | *ALNRGT | Alings the column to the right. | | *CVTLBL | Create a label (alphanumnerical) not a numerical cell. |
|
|
| Line Types (LINTYPES) | This parameter tells i-effect explicitly which lines in a report are to be treated as page or column headings. If any lines are identified as headings with this parameter, all other lines will be treated as data lines . Single Values: | *NONE | No line types defined. i-effect is trying to determine the line type based on statistical and positional criteria. |
This parameter contains 9 elements: | From Page Number | Specify the first page number to which the definition relates. A negative number is interpreted as counting from the end of the report. For example, -1 is the last page, -2 the penultimate page etc. | *FIRST | The first page. | | *LAST | The last page. |
| | Until Page Number | Specify the last page number to which the definition relates. A negative number is interpreted as counting from the end of the report. For example, -1 is the last page, -2 the penultimate page etc. | *FIRST | The first page. | | *LAST | The last page. |
| | From Line Number | Enter the first line number to which the definition relates. | *FIRST | The first line. | | *LAST | The last line. |
| | Until Line Number | Enter the last line number to which the definition relates. | *FIRST | The first line. | | *LAST | The last line. |
| | Line Type | | *PAGHDG | The line belongs to the page heading. | | *COLHDG | The line belongs to the column heading. |
| | Conversion Method | File allocation for this line. | *COLUMNS | The data is mapped columns. | | *LINE | The data is treated as a line and not separated into columns. |
| | Keep column? | Whether and when to keep lines of this type in the output or be removed. | *DFT | Default action:
- If the line (* PAGHDG indicated above) is identified as the page heading that option from the EXCEL parameter is used, which controls the removal of the page headers
- If the row is identified as a column header (* COLHDG indicated above), the option from the EXCEL parameter is used, which controls the removal of the column headings
- If the line (* OTHER indicated above) is identified as other line, duplicate lines are removed after the first line.
| | *NONE | All lines that are identified by this parameter are removed. | | *ALL | All lines that are identified by this parameter remain. | | *FIRST | All duplicate rows after the first to be identified by these parameters are removed. |
| | Key characters for review | Specifies a string for review. contain only rows that match the sides and Zeilenkritieren from above, and dieauch this (case sensitive sensitive) search string are selected by this rule. | *NONE | There is no search string tested. Only the pages and lines criteria are applied. | | key | Specifies the search string. |
| | Line Type Name | Specifies a name for this line type. This name can be used to identify the line type in the APYSTYLES and CNDFMTGRP parameters. | *NONE | No name is linked to the line type. | | line_type_name | Enter a name for the line type. The name can contain up to 20 characters, but must comply with the normal rules for OS / 400 corresponding name. |
|
|
| Conditional Formatting groups (CNDFMTGRP) | Determines rulesets conditional formatting. A rule group for conditional formatting defines a set of related rules that are applied in a specific order of priority on a range of cells to determine the appearance of the cells. You could, for example, define a rule that checks the value of the field ■ account balance of the customer ■ and in case of a negative value, a red mark in a positive value, however, focuses a green marker.
See the CNDFMTRULE parameters See below for examples of conditional formatting. Single Values: | *NONE | There was no conditional formatting specified. | | *OTHER VALUES | (Up to 1000 repetitions) |
| Control group number | Specifies an arbitrary positive integer, different from zero, which identifies the control group. In order to identify the group, you can choose any number, but they can appear for all rulesets defined in the instruction only once. The CNDFMTGRP parameter defines attributes at the group level such as the range of cells for which the rules apply, whereas the individual rules of the group of CNDFMTRULE parameter defines which are checked in the order previously set against those cells. 1-32767
| Enter a control group number. |
| | Control group Namen | Specifies an optional, any name that identifies the control group. The name can be freely wählen.Dieser helps to determine the specific rule groups and their purpose, but has no other function. | *NONE | The group got no name. | | name | Enter the group's name. |
|
|
| Apply to rows / columns | Returns the rows in the worksheet to which the rules should be applied.
Single values: *ALL
| The rules are applied to all the rows in the worksheet, on the lines that do not contain any data. When new data is input after the last line, the rules are applied to these. | | Other values | |
Alternatively, you can specify the function of which is to identify the data to which the rules are to be applied between 1 and 50 mapping references (CVTSPLXL) or references to rows / columns (CVTSPLXLS). | character value | Specify the row / column reference in one of the following forms: | line_type_name | all cells in the rows that have been associated with a range defined by the LINE TYPES parameter line type, where the name matches line_type_name and the column letter col istz.B. header_line | | line_type_name(col) | all cells in the rows that have been associated with a range defined by the LINE TYPES parameter line type,, where the name matches line_type_name and the column letter is as col Header_line (A) | | line_type_name(colline) | all cells in the rows that have been associated with a range defined by the LINE TYPES parameter line type, where the name matches line_type_name, the column letter is col and the relative line number in the stanza line, for example, Header_line (A2) |
|
| Conditional Formatting Rule (CNDFMTRULE) | Are the rules of conditional formatting. A rule group for conditional formatting defines a set of related rules that are applied in a specific order of priority on a range of cells to determine the appearance of the cells. You could, for example, define a rule that checks the value of the field balance of the customer and in case
a negative value a red marker, with a positive value, however setzt.usw a green marker. The CNDFMTGRP parameter specifies rulesets conditional formatting and attributes at the group level, such as the range of cells to which the group rule is applied.
The CNDFMTRULE parameter defines the individual rules within these groups, which are examined in turn.
Please note that Excel does not support all of the attributes that may be specified for a style with the DFNSTYLE parameters or the CRTSTLDFN command if conditional formatting is used. The number of attributes that are specified for conditional formatting is even more limited when you spend in * .xls. In particular, the number of formats, fonts and font sizes can not be changed when you spend in * .xls. Limitations also exist in relation to the types of tests that used in the output in * XSL format Single Values: | *NONE | There were given no rules for conditional formatting. | | Other Values | (Up to 50 repetitions) |
| Control group number | Specifies an arbitrary positive integer, different from zero, which identifies the control group. To identify the group, you can choose any number, but they can appear for all control groups defined in the command only once.
The CNDFMTGRP parameter defines attributes at the group level such as the range of cells for which the rules apply, whereas the individual rules of the group of CNDFMTRULE parameter defines which are checked in the order previously set against these cells. 1-32767
| Enter the group number as the CNDFMTGRP Parameter is defined. |
| | rule priority | The priority of the rule for conditional formatting. If the group includes more than one rule, this value is used to determine which rule takes precedence over
and thus which style is applied. Low numerical values give a higher priority than high numerical values, that is, 1 has the highest priority. 1
| Priority 1 | | 1-32767 | Enter the rule priority |
| | To be checked box | Specifies the data item in the report, which is checked with a rule to determine whether the rule is right or wrong. *CELLIS
| The logical test checks every single cell within the data range to which the rule is applied and not to a specific column. For example if you use rules for conditional formatting to apply different colors, and a * CELLIs specify rule, then every single cell in the cell area to which the rules are applied, have different colors, depending on the values of the individual cells. | *FORMULA
| Enter in the (listed below?) Parameter value 1 element a formula. This formula determines whether the rule is right or wrong, and therefore which style is applied. Not supported on output * XLS. | Excel_col_ref
| Specify an Excel column letters. i-effect Spool Converter creates a formula which performs the required logic test against the value of this column, in the row to which the rule applies. For each line, to which applies the aforementioned rule, the value of this column is in each row specify the format of the latter.
If the file contains, for example, customer account details and you want to assign nachKontostand various colors lines each, and assumed that the balance in the M column, so you would type the column M here, since this is the field that defines the formatting of lines
| | applicable test | Specifies the logical test that is performed to determine whether the rule is true or false, and thus determines the appropriate style. | *NONE | No. Only valid when * FORMULA specified in the previous item, that is You must specify below your own formula that is applied to the parameter value 1 element. Compare The remaining tests the value of the field that was identified with the previous parameter element, or each cell (if * CELLIs specified) against the parameter value or values that have been specified 2 elements in the parameter value 1 and parameter value. | *EQ
| Equal.
A single value must be specified in the parameter value. 1 The rule is true if the field or cell value equals this value. | *GT
| Greater than.
A single value must be entered below the parameter value. 1 The rule is true if the field or cell value is greater than this value. | | *LT | Less than.
A single value must be specified in the parameter value. 1 The rule is true if the field or cell value is less than this value. | | *GE | Greater than or equal.
A single value must be specified in the parameter value. 1 The rule is true if the field or cell value is greater than or equal to this value. | | *LE | Less than or equal.
A single value must be specified in the parameter value. 1 The rule is true if the field or cell value is less than or equal to this value. | | *NE | Unequal.
A single value must be specified in the parameter value. 1 The rule is true if the field or
Cell value is not equal to this value. | | *BETWEEN | In between.
Two values must be specified in the value parameter 1 and parameter value of 2. The rule is true if the field or cell value is greater than or equal to the first value and less than or equal to the second value. | | *NOTBETWEEN | Not between.
Two values must be specified in the value parameter 1 and parameter value of 2. The rule is true if the field or cell value is less than the first value and larger than the second value. | | *CT | Includes.
A single value must be entered in the parameter value 1 and it is interpreted as a string. The rule is true if the field or cell value contains the string.
Not supported on output * XLS. | | *CONTAINS | Same as *CT | | *NC | Does not include.
A single value must be entered in the parameter value 1 and it is interpreted as a string. The rule is true if the field or cell value does not include the string.
Not supported on output * XLS. | *NOTCONTAINS
| Same as *NC | | *BEGINSWITH | Begins with.
A single value must be entered in the parameter value 1 and it is interpreted as a string. The rule is true if the field or cell value starts with the specified string.
Not supported on output * XLS. | *ENDSWITH
| Ends with.
A single value must be entered in the parameter value 1 be and it is interpreted as a string. The Rule is true if the field or cell value with the specified string ends. Not supported on output * XLS. | *BLANKS
| Includes space. The value of parameter value 1 is irrelevant and is ignored. The rule is true if the cell or is field value blank (empty or contains only Spaces). Not supported on output * XLS. | | *NOTBLANKS | Does not include spaces.
The value of parameter value 1 is irrelevant and is ignored. The rule is true if the cell or field value is not empty (it is empty or contains not only spaces). Not supported on output * XLS. | | *TIMEPERIOD | Timeperiod.
The value of the parameter value 1 has one of the following time values (* LAST MONTH, etc.) correspond. The rule is true if the field or cell value is a number that can interpret Excel as a date and if this date corresponds to the specified period. |
The value of the parameter value 1 has one of the Following time values (* LAST MONTH, etc.) correspond. The rule is true if the field or cell value is a number did can interpret Excel as a date and if this date corresponds to the specified period. | *TOPN | Highest nc values.
n values. With the * TOPN option you have the opportunity to highlight the highest n values, where n is a number you choose. Example, if you have a list of 100 bills and 10 bills of which the highest value would like to emphasize, as you would specify 10 (the highest 10 values) for the parameter value. 1 Not supported on output * XLS. | | *BOTTOMN | Smallest values.
The parameter value of 1 indicates the value of n. The rule is true if the field or cell value is in the bottom n values. Not supported on output * XLS. | *TOPNPC
| Supreme percent.
The parameter value of 1 indicates the value of n. The rule is true if the field or cell value is in the highest n percentage of values. Not supported on output * XLS. | | *BOTTOMNPC | Lowest percentage. The parameter value of 1 indicates the value of n. The rule is true if the field or cell value is in the lowest n percentage of values. Not supported on output * XLS. | *DUPLICATE
| duplicate values
The value of parameter value 1 is irrelevant and is ignored. The rule is true if the field or cell value occurs more than once in the cell area. Not supported on output * XLS. | | *UNIQUE | duplicate values
The value of parameter value 1 is irrelevant and is ignored. The rule is true if the field or cell value occurs exactly once in the cell area. Cell value occurs exactly once in the cell area. Not supported on output * XLS. |
|
| | Parameter Value 1 | The first parameter value which is required for the examination above.
The interpretation of the parameter element depends on the value of the test to be performed from: | *EQ, *LT, *LE, *GT, *GE, *NE | A value representing a number or string, e.g., 1000, New York | | *BETWEEN, *NOTBETWEEN | The first 2 values in the pair is a number or string. The second value of the pair of values in the parameter value 2 will enter, for example, 1000, A | | *CT, *NC, *CONTAINS, *NOTCONTAINS, *BEGINSWITH, *ENDSWITH | A value representing a string, e.g., New York | *TIMEPERIOD
| Must represent one of the listed timeframes values as * LAST MONTH. | *TOPN, *BOTTOMN
| The ranking value, for example, 10 = "Maximum 10" | | *TOPNPC, *BOTTOMPC | The percentage value, for example, 10 = "Highest 10%"
If testing is to be applied is * TIME PERIOD The value must be one of the following time frame values: | *THISMONTH | This month. The date is in the current calendar month. | | *LASTMONTH | Last month. The date is in the previous calendar month. | | *NEXTMONTH | Next month. The date is in the next calendar month. | | *THISWEEK | This week. The date is in the current week. | | *LASTWEEK | Last week. The date is in the previous week. | | *NEXTWEEK | Next week. The date is in the next week. | | *LAST7DAYS | Last 7 days. The date is the period within the last 7 days. | | *TODAY | Today. The date is the current DAY. | | *YESTERDAY | Gestern. Das Datum ist der gestrige Tag. | | *TOMORROW | Yesterday. The date is the day yesterday. |
If specified as test * FORMULA, you must enter your own formula in this parameter element. If the result of this formula is true, the style is applied, which has been assigned to this rule. If you specify cell references in the formula, then the line number of the first data row of the worksheet should match with the column headers and additional headers are involve. Use the relative row reference to test each cell individually in the area, or an absolute column reference to check the value of a specific column. Please catch the formula NOT with an equal sign =, as you would do it in a cell.
There is another special value: * AVG. With this you can check the average value for the selected range. This is only permitted if:
- The field to be checked is: * CELL
- The appropriate test is: * EQ, * GT * LT, LE * or * GE
|
| | Parameter Value 2 | The second parameter, which is required for the above examination.
The default is * NONE.
If the test * BETWEEN or * NOTBETWEEN is * NONE must not be specified. The value entered must match the value that was specified as a parameter value 1, to be equal to or greater than he.
A value other than * NONE must be specified for all other tests.
For more information about specifying values see the previous item. | | Applicable style name | The name of the applied style, if the rule is true. The name of the style must match the defined WRKSTLDFN or CRTSTLDFN style.
Please note that Excel does not allow all the attributes that can be defined for a style with conditional formatting. If you indeed change the text color and represent the font bold or italic, font or size, you can not change, however. If you still try to change them with conditional formatting, Excel will ignore these changes *NORMAL
| The normal style. | character-value
| Specify the name of the style. Please note the uppercase and lowercase letters. |
| | Stop if true | Specifies whether Excel stops to examine the rules in the group once one of which is interpreted as true, or whether it continues to test and next rules checked. | *YES | If this rule evaluates to true, no other rules can be applied with a lower priority in front of her. | | *NO | Other rules that have a lower priority, are also tested and can share cancel the formatting. |
Examples The following examples assume that the WRKST DFN or CRTSTLDFN used command to define styles that RED, ORANGE and YELLOW hot (which could for example, change the color of the cell background in red, orange or yellow). Example 1:
CODE
CVTSPLXL
FROMFILE(CUSTACCT)
...
CNDFMTGRP( (1 BALANCES *DETAILS)
(2 DUESOON *ALL '*DETAILS(N)'))
CNDFMTRULE( (1 1 M *LT 0 RED *YES)
(1 2 M *BETWEEN 0 100 ORANGE)
(2 1 N *TIMEPERIOD *NEXTMONTH *NONE YELLOW))
Here the customer report is converted to an Excel worksheet. 2 groups with conditional formatting rules are defined:
- BALANCES which all detail lines (which were not specified by LINTYPES) is applied and 2 rules has:
-When the value in the M null column, the entire line is highlighted in red.
-When the value in the M null column, the entire line is highlighted in red - DUESOON which is applied only to the date in the column N of the detail rows. This has one rule
- If The date is in the N column in of next calendar month, then the YELLOW style is applied.
|
|
| Pagesize (PAGESIZE) | Determines the size and orientation of the page that will be used. Special Values: | *CALC | i-effect assumes a paper size based on the country code of the current job. Letter is assumed, if the country code US (United States) or CA (Canada), otherwise A4 paper is assumed. |
| Paper Format | The description of this parameter can be found under Menu item 11: Convert spool file to PDF (CVTSPLPDF) Part 1Except values *SPLF, *DEVD and *CUSTOM. | | Orientation | The description of this parameter can be found underMenu item 11: Convert spool file to PDF (CVTSPLPDF) Part 1 | | Page Scaling Method | Determines how data is scaled to fit to the page. | *NONE | No scaling is applied. | | *FIT | The data is fitted to a specified number of pages wide by a specified number of pages tall. The number of pages wide and tall are specified with the parameter's 5th and 6th elements. | | *ADJUST | The data is adjusted to fit the page by a scaling percentage. The percentage is specified with this parameter's 4th element. |
| | Percentage Adjustment | The scaling percentage to apply when *ADJUST is specified as scaling method. | 100 | 100% (No changes) | | 0-400 | The scaling percentage. Only whole numbers are allowed. |
| | Fit to Pages Wide | The number of pages wide (horizontal scaling), to which the data will be fitted. | *AUTO | Excel calculates the number of pages required. | | 0-65535 | Number of pages. |
| | Fit to Pages Tall | The number of pages tall (vertical scaling), to which the data will be fitted. | *AUTO | Excel calculates the number of pages required. | | 0-65535 | Number of pages. |
| | Print Gridlines | Determines if the gridlines should be printed. | *NO | Gridlines will not be printed. | | *YES | Gridlines will be printed. |
|
|
| SPLIT | The description of this parameter can be found underMenu item 11: Convert spool file to PDF (CVTSPLPDF) Part 1 |
| SPLITPAGE | The description of this parameter can be found underMenu item 11: Convert spool file to PDF (CVTSPLPDF) Part 1 |
| SPLITPOS | The description of this parameter can be found underMenu item 11: Convert spool file to PDF (CVTSPLPDF) Part 1 |
| EXITPGM | The description of this parameter can be found underMenu item 11: Convert spool file to PDF (CVTSPLPDF) Part 1 |
| EXITPGMPRM | The description of this parameter can be found underMenu item 11: Convert spool file to PDF (CVTSPLPDF) Part 1 |
| EXITPGMPOS | The description of this parameter can be found underMenu item 11: Convert spool file to PDF (CVTSPLPDF) Part 1 |
| EXITPGMKEY | The description of this parameter can be found underMenu item 11: Convert spool file to PDF (CVTSPLPDF) Part 1 |
| TEXT | The description of this parameter can be found underMenu item 11: Convert spool file to PDF (CVTSPLPDF) Part 1 |
| DBCS | The description of this parameter can be found underMenu item 11: Convert spool file to PDF (CVTSPLPDF) Part 1 |
| EXCLPAGNBR | The description of this parameter can be found underMenu item 11: Convert spool file to PDF (CVTSPLPDF) Part 1 |
| EXCLPAGKEY | The description of this parameter can be found underMenu item 11: Convert spool file to PDF (CVTSPLPDF) Part 1 |
| Exclude Line Number (EXCLLINNBR) | Determines line in the spooled file that will be excluded from conversion.
This option can be used to suppress not required line numbers from output.
Single Values: | *NONE | No lines will be exlcuded. | | Other Values | (Up to 20 repetitions) The line number where the exclusion is to begin. All lines in the output file from this line will be excluded unitl the number of lines has been reached, which is entered in the next parameter. |
This parameter contains 4 elements: From Line | | 1-999 | Enter the number where the exclusion is to begin. |
| | Number of Lines | This is the number of lines, which will be excluded from every page starting with the line number entered above. | 1 | Excludes exactly one line. | | 1-999 | The number of lines, which will be excluded. |
| | Exclude From Page | The lines will only be excluded from the specified page.
Please note: This page number refers to the relative page number within the group of pages selected by splitting, not the absolute page number in the original spooled file. For example, if a 30-page spooled file is split into 3 10-page sections, and if page number 2 is specified, it would refer to pages 2, 12 and 22 in the original spooled file. | *FIRST | The exlcluded section begins with the first page. | | 1-9999999 | Enter the page number within the split file, where the excluded section begins. |
| | Exclude Until Page | The lines will only be excluded up to the page specified.
Please note: this page number refers to the relative page number within the group of pages selected by splitting, not the absolute page number in the original spooled file. For example, if a 30-page spooled file is split into 3 10-page sections, and if page number 2 is specified, it would refer to pages 2, 12 and 22 in the original spooled file. | *LAST | The excluded section will continue up to the last page. | | 1-9999999 | Enter the page number within the split file, where the excluded section should end. |
|
| RSCDIR | The description of this parameter can be found under: Menüpunkt 11: Spooldatei in PDF konvertieren (CVTSPLPDF) Teil 1. | | STMFCODPAG | The description of this parameter can be found under: Menüpunkt 11: Spooldatei in PDF konvertieren (CVTSPLPDF) Teil 1. | | SPLFCCSID | The description of this parameter can be found under: Menüpunkt 11: Spooldatei in PDF konvertieren (CVTSPLPDF) Teil 1. | | AUT | The description of this parameter can be found under: Menüpunkt 11: Spooldatei in PDF konvertieren (CVTSPLPDF) Teil 1. | | Suppress underlining | This parameter specifies whether consecutive underscores should be removed. | *YES | Consecutive underscores are removed | | *NO | Consecutive underscores are not removed |
| | Column separator character | If the parameter COLUMN OTP (* TOKEN) is specified, the data from the spool file will be divided according to this value to the Excel columns.
The default value is * SPLF, and states that are divided according to the structure of the spool file into Excel columns values. If the spool file was created by an external described printer file, this value provides probably the best result since the data is sorted in the spool file so that any logical or natural element is converted into a Sepearates identifiable element.
However, if the spool file Outlined by an internal printer file or an application, have been as Query created / 400, so the data is in a single logical block are summarized. In this case, it is better to provide a value andem the data can be separated. | *SPLF | The separator is to be recognized and used based on the printer file. | | *BLANK | Equivalent to a blank |
| | Number of column separators | Specifies the number of times that must be followed by the separator character come together to create a new column. |
This option gives you influence the way in which the i-effect algorithm operates to calculate the column positions. The algorithm uses statistical methods to determine the positions in the report, where left-aligned alphanumeric or right justified numeric data columns appear. The algorithm determines these positions, if appropriate blocks occur at a frequency at the location, which is above a predetermined number of standard deviations. The value specified here is the number of standard deviations to use. When the default value (1 standard deviation from the norm) does not give the desired results, you can try here to set this to a different value.
line_type_name (col)
all the cells in the rows, the one by the
LINTYPES parameters defined line type assigned
were ,, where the name matches line_type_name
and the column letter is as col Header_line (A) |
| Exclude Lines Based on a Key (EXCLLINKEY) | Determines lines in the report, which should be excluded from the output, based on the appearance of a key string
Single Values: | *NONE | No lines will be excluded. | | Further Values | (Up to 20 repetitions) |
This parameter contains 6 elements: | Exclude Lines with Text | Specify a key string. Every line, which contains this key string, will start a set of lines, which will be excluded. The number of lines specified with the following element will be excluded from the output from that point on. | character-value | Specify the key string. This is case-sensitive and should be enclosed in single quotes if a lower-case or mixed-case value is to be checked for. |
| | Number of Lines | Enter the number of lines from the occurrence of the key string, which will be excluded from conversion. | 1 | Excludes exactly one line. | | 1-999 | The number of lines, which will be excluded. |
| | Exclude From Page | The lines will only be excluded from the specified page. Please note: This page number refers to the relative page number within the group of pages selected by splitting, not the absolute page number in the original spooled file. For example, if a 30-page spooled file is split into 3 10-page sections, and if page number 2 is specified, it would refer to pages 2, 12 and 22 in the original spooled file. | *FIRST | The exlcluded section begins with the first page. | | 1-9999999 | Enter the page number within the split file, where the excluded section begins. |
| | Exclude Until Page | The lines will only be excluded up to the page specified.
Please note: this page number refers to the relative page number within the group of pages selected by splitting, not the absolute page number in the original spooled file. For example, if a 30-page spooled file is split into 3 10-page sections, and if page number 2 is specified, it would refer to pages 2, 12 and 22 in the original spooled file. | *LAST | The exlcluded section ends with the last page. | | 1-9999999 | Enter the page number within the split file, where the excluded section ends. |
| | Options | Whether rows excluded or not based on the string that occurs on the line or not. | *CT | Includes. If the line the string "includes", so if the string appears in the row, the row is excluded from the output. | | *NC | Nicht beinhaltet. Wenn die Zeile die Zeichenfolge "nicht beinhaltet", wenn also die Zeichenfolge in der Zeile nicht vorkommt, wird die Zeile von der Ausgabe ausgeschlossen. |
| | Logical connection to the next test | The logical link to the next defined in this EXCLLINKEY parameter test.
Where several EXCLLINKEY parameters are defined, each parameter can be considered as a separate test. This element specifies how this test is logically connected to the next test. | *OR | The logical link between this test and the next test is a "or" link.
Each "or" link starts a new group of tests, ie when the value of this element * OR, istdieser test independent of the next. | | *AND | The logical connection between this test and the next test is a "and" link.
The rule is true, and the row is ausgeschlossennur if ALL tests that are with "and" Connected, are true.
The value in the last text is ignored.
Example 1:
CODE
CVTSPLCSV
EXCLLINKEY((test1 1 *FIRST *LAST *CT *OR)
(test2 1 *FIRST *LAST *CT))
A single line will be excluded if they read either "test1" or the text "test2".
Example 2:
CODE
CVTSPLCSV
EXCLLINKEY((test1 1 *FIRST *LAST *CT *AND)
(test2 1 *FIRST *LAST *CT))
A single line is removed if it contains both the text "test1" and the text "test2". |
|
|
| RSCDIR | The description of this parameter can be found underMenu item 11: Convert spool file to PDF (CVTSPLPDF) Part 1 |
| STMFCODPAG | The description of this parameter can be found underMenu item 11: Convert spool file to PDF (CVTSPLPDF) Part 1 |
| SPLFCCSID | The description of this parameter can be found underMenu item 11: Convert spool file to PDF (CVTSPLPDF) Part 1 |
| AUT | The description of this parameter can be found underMenu item 11: Convert spool file to PDF (CVTSPLPDF) Part 1 |
| Suppress underlining | This parameter specifies whether or not consecutive underline characters will be removed. | *YES | Consecutive underline characters will be removed. | | *NO | Consecutive underline characters will not be removed. |
|
| Column separator character | If the parameter COLUMNOPT(*TOKEN) has been specified, the data from the spooled file will divided into the Excel columns according to this value. The default value *SPLF indicates that the values will be separated into Excel columns based on the structure of the spooled file. If the spooled file was created from an externally described printer file, this value probably will provide the best results, because the data in the spooled file is sorted so that every logical and natural element is converted into a separately identifiable element. If the spooled file was created be an internally described printer file or an application like Query/400, the data is summarized in one single logical block. In this case, it is better to enter a value that can separate the data. | *SPLF | The separator will be recognized and used according to the printer file | | *BLANK | Is one blank. |
|
| Number of Column Separators | Specifies how often the separator character must occur consecutively in order to generate a new column. |