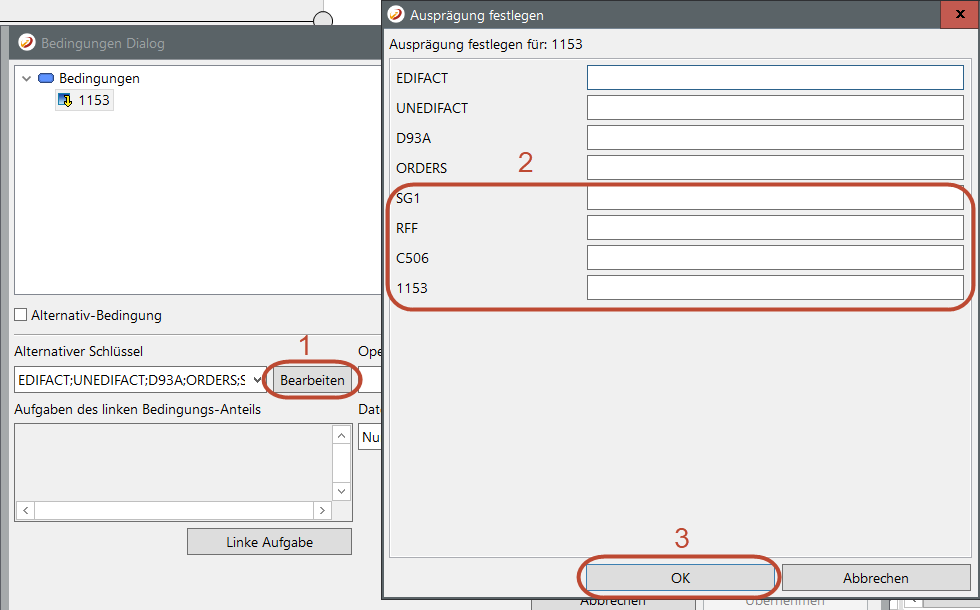
Occurences of a data elements
he mapper core generally sorts mapped values within the target module according to the auto-occurrence principal which means:
- Search for the next free spot in the target data structure for the value in the mapping.
If the framework of the mapped target element doesn't exist, it will be created. For example, for EDIFACT, if a value should be written into a seg-ment's specific data element, the groups, if non-existent and the segment as well, will be created and then the value written.
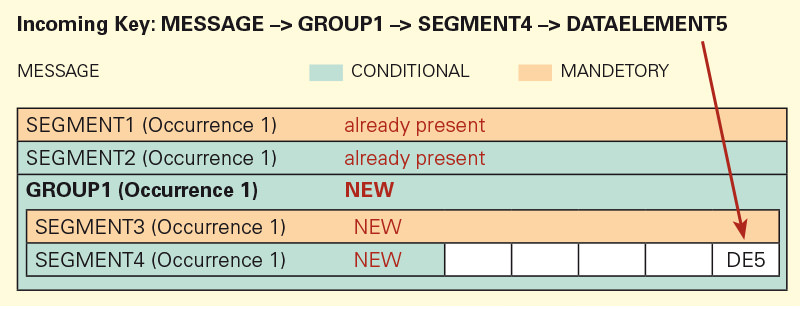
If an additional value should be written into the same data element in the structure, an addition, new segment will be created and the value will be written into the new segment.
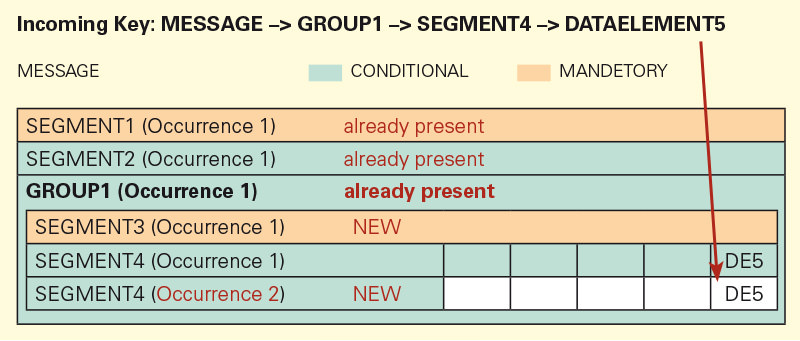
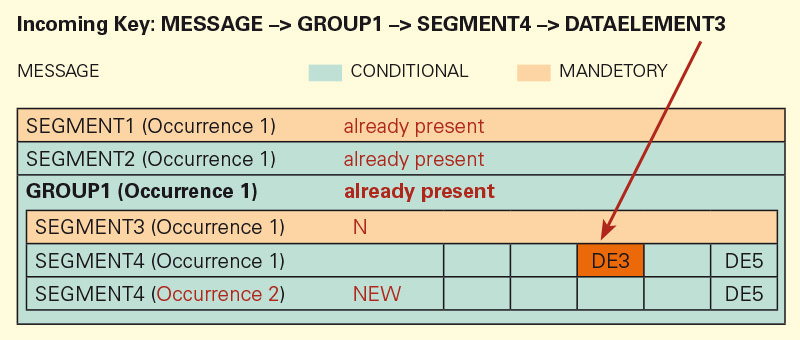
In the second depiction, SEGMENT4 was created a second time in the group, because it can occur more than once at this position.
Certain segments do not allow duplicates. In such cases, auto occurrence functions differently. If a data element (DE3) was written into SEG-MENT3. SEGMENT3 is a must segment, and introduces a group, which is why it can only exist once in the group. If SEGMENT3 exists more than once, the group would then exist more then once (in this example, GROUP1 can exist more than once in the structure).
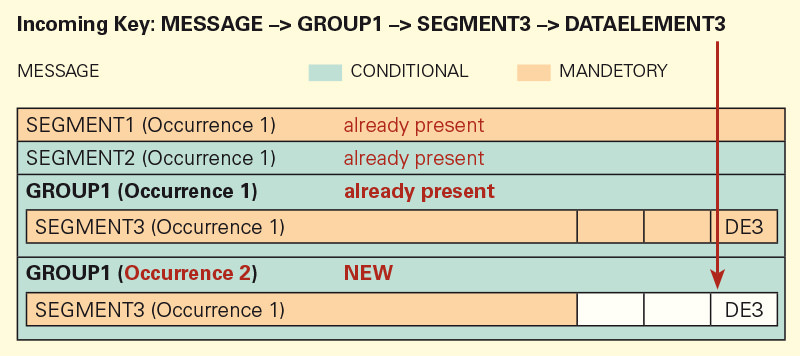
Auto-Occurrence recognizes that SEGMENT3 already exists that already has a value written at DE3. Because there cannot be more then one SEGMENT3, the next higher level that can have a repeatable group will be tested.
A new group will be created with a new SEGMENT3 and DE3 will be written into it.
The reason that SEGMENT3 is the first repetition is that it is the first occurrence within GROUP1 (repetition 2).
The occurrence is dependent on the level in which the element is located.
Limits auto-occurence
Auto-occurrence reaches it's limits, if it is possible that not every data element per segment/record is filled in repeated segments/records. Such a situation occurs if several data elements within a segment/record are conditional elements and need not be filled.
In this example, SEGMENT4 was filled with DE5. There were no further values for this group (the VALUE DE3 does not exist in the first repetition).There are more values for SEGMENT4 → DE5. A new SEGMENT4 will be created and the value will be written into DE5 of the new segment. In this case there is another value for SEGMENT4 (Repetition 2). Because DE3 in SEGMENT4 (repetition 1) was not filled, Auto-Occurrence looks for the next DE3 field and writes the value into SEGMENT4 (repetition 1). In this case, the value was written incorrectly.
Why does Auto-Occurrence work this way?
This is how Auto-Occurrence basically functions. Because of the any-to-any concept, the order in which the values will be taken from the source side, and if this order corresponds exactly to the target module's structure cannot be definitively stated. This is why it is per-determined that Aeto-Occurrence will write a value in the first free field. If there are repetitions of a field group (e.g. for field group: segment, record), the first free field in the existing groups will be found.
Example
The data comes in the following order:
→ MESSAGE → GRUPPE1→ SEGMENT4 → DATAELEMENT5
- (DE5's Value belongs to position 1)
- → MESSAGE → GRUPPE1 → SEGMENT4 → DATAELEMENT5
(DE5's Value belongs to position 2) - → MESSAGE → GRUPPE1→ SEGMENT4 → DATAELEMENT3
(DE3's Value belongs to position 1) - → MESSAGE → GRUPPE1 → SEGMENT4 → DATAELEMENT3
(DE3's Value belongs to position 2)
Auto-Occurrence would assign the data correctly.
In another situation (other source structure) the data comes in the following order:
- → MESSAGe → GRUPPE1 → SEGMENT4 → DATAELEMENT5
(DE5's Value belongs to position 1) - → MESSAGE → GRUPPE1 → SEGMENT4 → DATAELEMENT3
(DE5's Value belongs to position 1) - → MESSAGE → GRUPPE1 → SEGMENT4 → DATAELEMENT5
(DE3's Value belongs to position 2) - → MESSAGE → GRUPPE1 → SEGMENT4 → DATAELEMENT3
(DE3's Value belongs to position 2)
Auto-Occurrence would assign the data correctly.
Data occurs in the order described under Limits of AUTO-occurrence:
- → MESSAGE → GRUPPE1 → SEGMENT4 → DATAELEMENT5
(DE5's Value belongs to position 1) - → MESSAG → GRUPPE1 → SEGMENT4 → DATAELEMENT3
(DE5's value belongs to position 1) - → MESSAGE → GRUPPE1 → SEGMENT4 → DATAELEMENT5
(DE3's Value belongs to position 2) - → MESSAGE → GRUPPE1 → SEGMENT4 → DATAELEMENT3
(DE3's Value belongs to position 2)
Auto-Occurrence would assign the data incorrectly (see the diagram in Limits AUTO-Avoiding Problems
Avoiding Problems
There are two ways to deal with this issue:
- Closing groups or segments/records after all the data of an information unit was written.
- Specifying the repetition of the group or segment/record into which the data field's value will be written.
For 1.: see above Working with Write-Triggers and Write-Triggers of Modules other than-DB (Close-Trigger)
For 2.: see Defining Occurrence with Sources (Group, Element) and Targets
Defining Occurrence with Sources (Group, Element) and Targets
The mappings previously discussed were all point to point mappings. A source value is assigned to a target value. Even if a value was assigned to several targets, it is still only one mapping.
An element can occur several times. E.g. the date segment DTM can occur many times in row in EDIFACT. Until now, the discussion here has not covered how it is possible to specify which occurrence of an element should be used for a specific mapping.
Every occurrence of a DTM at the same position within the data definitions structure (directories) is structured the same and cannot be differentiated from others.
It is possible to determine which occurrence is important, if required.
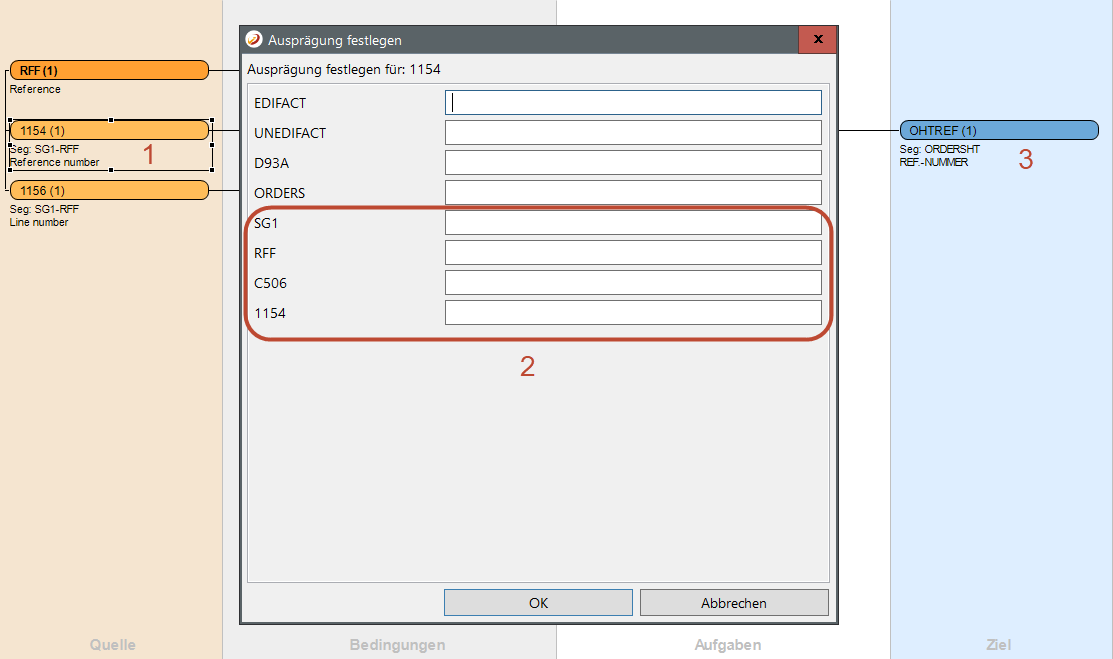
Double clicking on one of the fields 1 or selecting the corresponding context menu opens a dialog for specifying the exact occurrence of the ele-ment. The dialog displays all key parts for determining a data element within the directory.
For every key part a corresponding value for the occurrence can be determined 2. Opening the dialog again displays the previously entered values.
In this way, specified mappings are carried out during the mapping process only with the correct source data elements.
This also applies to the write direction. In this case, these specifications place the target data within the output data structure.
Defining Occurrence with Conditions
Occurrences can also be defined for more than source and target elements. Referential source elements used in conditions can also be specified.
Open a condition in the edit mode from the condition dialog. Clicking on 1 opens the Define Occurrence dialog. If desired the occurrences can be set with 2 and saved using 3.