Vorkommmen (Occurences) eines Datenelements
Der Mapper-Core arbeitet standardmäßig bei der Einsortierung von gemappten Werten innerhalb des Zielmoduls nach dem Prinzip der Auto-Occurrence (bzw. Vorkommen, Ausprägung), was soviel bedeutet wie:
- Suche den nächsten freien Platz innerhalb der Zieldatenstruktur für den zu mappenden Wert.
Existiert der Rahmen der Datenstruktur um das zu mappende Zielelement nicht, wird diese erzeugt. Soll beispielsweise bei EDIFACT in ein bestimmtes Datenelement eines Segments ein Wert geschrieben werden, werden evtl. nicht vorhandene Gruppen und das entsprechende Segment erzeugt und der Wert geschrieben.
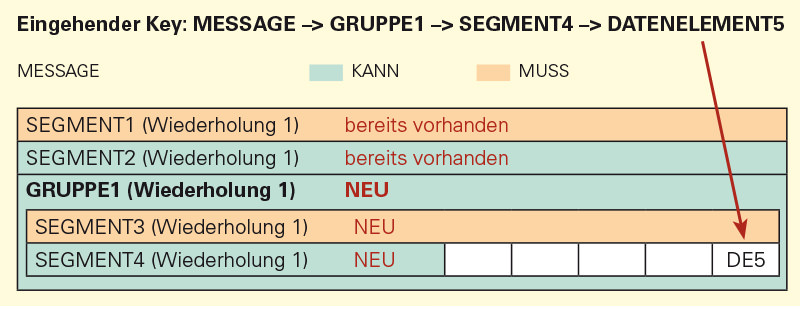
Soll jetzt eine weiterer Wert in das gleiche Datenelement in der Struktur geschrieben werden, wird entsprechend ein weiteres, neues Segment erzeugt und der Wert in dieses neue Segment geschrieben.
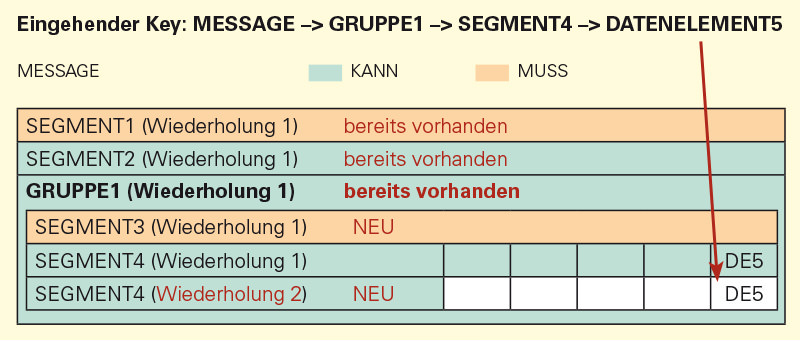
In dieser zweiten Grafik wurde das SEGMENT4 innerhalb der Gruppe ein zweites mal erzeugt, da es wiederholt an dieser Stelle vorkommen darf.
Es kann aber auch Segmente geben, die keine Wiederholung zulassen. In solchen Fällen verhält sich die Auto-Occurrence entsprechend anders. Gehen wir davon aus, es wurde ein Datenemelent (DE3) in das SEGMENT3 geschrieben. SEGMENT3 ist ein MUSS-Segment und leitet die Gruppe ein. Daher darf es nur einmal innerhalb der Gruppe vorkommen. Ein Mehrfachvorkommen von SEGMENT3 würde bedeuten, dass die Gruppe mehrfach existiert (Die GRUPPE1 darf in unserem Beispiel mehrfach in der Struktur vorkommen).

Auto-Occurrence erkennt in diesem Fall, dass bereits ein SEGMENT3 vorhanden ist, welches bereits einen Wert an der Stelle DE3 geschrieben hat. Da sich das SEGMENT3 nicht wiederholen darf, wird die nächst höhere Ebene geprüft, bei der es sich um eine wiederholbare Gruppe handelt.
Es wird eine neue Gruppe erzeugt mit einem neuen SEGMENT3, in welches das DE3 geschrieben wird.
Der Grund, weshalb SEGMENT3 die erste Wiederholung ist, liegt darin begründet, dass es innerhalb der GRUPPE1 (Wiederholung 2) das erste Vorkommen ist. Das Vorkommen wird immer in Abhängigkeit der Ebene gezählt, auf der sich ein Element befindet.
Grenzen von Auto-Occurence
Auto-Occurrence stößt an ihre Grenzen, wenn die Möglichkeit besteht, dass in sich wiederholenden Segmenten/Sätzen nicht jedes Datenelement je Segment/Satz gefüllt wird. Eine solche Situation ergibt sich, wenn mehrere Datenelement innerhalb eines Segments/Satzes KANN-Elemente sind und nicht zwangsläufig gefüllt werden müssen:
In dem hier gezeigten Fall wurde zunächst das SEGMENT4 mit dem DE5 gefüllt. Anschließend gab es für diese Gruppe keinen weiteren Wert mehr (sprich: der WERT für DE3 ist für die erste Wiederholung nicht vorhanden). Es folgt ein weiterer Werte für SEGMENT4 → DE5. Ein neues SEGMENT4 mit Wiederholung 2 wird erzeugt und der Wert nach DE5 geschrieben. In diesem Fall gab es aber einen weiteren Wert für das SEGMENT4 (Wiederholung 2). Da aber das DE3 von SEGMENT4 (Wiederholung 1) nicht gefüllt wurde, sucht sich die Auto-Occurrence das nächste freie Feld DE3 und schreibt den Wert nach SEGMENT4 (Wiederholung 1). In dieser Situation würde der Wert falsch geschrieben.
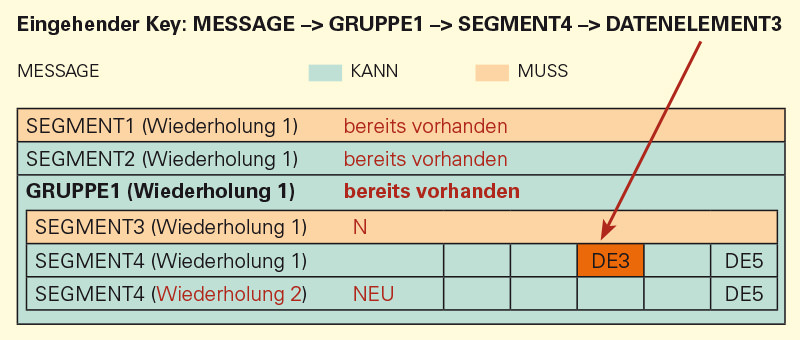
Warum verhält sich Auto-Occurence in dieser Art und Weise?
Es handelt sich dabei um das grundlegend definierte Verhalten von Auto-Occurrence. Aufgrund des Any-To-Any-Konzepts kann man nicht definiert sagen, in welcher Reihenfolge die zu schreibenden Werte von der Quellseite bereitgestellt werden und ob diese Reihenfolge der Struktur des Zielmoduls 1 zu 1 entspricht. Daher ist mit Auto-Occurrence festgelegt worden, dass ein Wert in das erste freie Feld geschrieben wird. Existieren mehrere Wiederholungen einer Feldgruppe (Beispiele für Feldgruppe: Segment, Satz) wird in den vorhandenen Gruppen das oberste freie Feld gesucht.
Beispiel
Die Daten kommen in folgender Reihenfolge:
- -> MESSAGE -> GRUPPE1 -> SEGMENT4 -> DATENELEMENT5
(Wert von DE5 gehört zu Position 1) - -> MESSAGE -> GRUPPE1 -> SEGMENT4 -> DATENELEMENT5
(Wert von DE5 gehört zu Position 2) - -> MESSAGE -> GRUPPE1 -> SEGMENT4 -> DATENELEMENT3
(Wert von DE3 gehört zu Position 1) - -> MESSAGE -> GRUPPE1 -> SEGMENT4 -> DATENELEMENT3
(Wert von DE3 gehört zu Position 2)
Auto-Occurrence würde die Daten korrekt zuordnen.
In einer anderen Situation (andere Quell-Struktur) kommen die Daten in folgender Reihenfolge:
- -> MESSAG -> GRUPPE1 -> SEGMENT4 -> DATENELEMENT5
(Wert von DE5 gehört zu Position 1) - -> MESSAGE -> GRUPPE1 -> SEGMENT4 -> DATENELEMENT3
(Wert von DE5 gehört zu Position 1) - -> MESSAGE -> GRUPPE1 -> SEGMENT4 -> DATENELEMENT5
(Wert von DE3 gehört zu Position 2) - -> MESSAGE -> GRUPPE1 -> SEGMENT4 -> DATENELEMENT3
(Wert von DE3 gehört zu Position 2)
Auto-Occurrence würde die Daten korrekt zuordnen.
Die Daten kommen wie in der Grenzsituation beschriebenen Reihenfolge:
- -> MESSAGE -> GRUPPE1 -> SEGMENT4 -> DATENELEMENT5
(Wert von DE5 gehört zu Position 1) - -> MESSAGE -> GRUPPE1 -> SEGMENT4 -> DATENELEMENT3
(Wert von DE5 gehört zu Position 1) - -> MESSAGE -> GRUPPE1 -> SEGMENT4 -> DATENELEMENT5
(Wert von DE3 gehört zu Position 2) - -> MESSAGE -> GRUPPE1 -> SEGMENT4 -> DATENELEMENT3
(Wert von DE3 gehört zu Position 2)
Auto-Occurrence würde die Daten falsch zuordnen (Siehe Grafik unter Grenzen von AUTO-Occurence).
Problemvermeidung
Es gibt zwei Ansätze, dieser Problematik zu begegnen:
- Gruppen oder Segmente/Sätze schließen, wenn alle Daten einer Informationseinheit geschrieben wurden.
- Angabe der Wiederholung der Gruppe oder des Segments/Satzes, in die der Wert eines Datenfeldes geschrieben werden soll.
Zu 1.: siehe Verwenden von Write-Triggern und Write-Trigger von NICHT-DB - Modulen (Close-Trigger)
Zu 2.: siehe Festlegen der Occurrence bei Quellen (Group, Element) und Zielen
Festlegen des Vorkommen (Occurrence) bei Quellen (Gruppe, Element) und Zielen
Die bisherigen Mappings entsprachen immer einem Punkt zu Punkt-Mapping. Ein Quell-Wert wird einem Ziel-Wert zugewiesen. Selbst wenn ein Wert mehreren Zielen zugewiesen wird, handelt es sich dabei um einzelne Mappings.
Jetzt kann es sein, dass ein Element mehrfach vorkommt. Z.B. das Datumssegment DTM bei EDIFACT kann mehrmals hintereinander vorkommen. Bisher haben wir nichts im grafischen Editor gesehen, mit dem es möglich ist, zu sagen, genau welches Vorkommen eines zu mappenden Elementes in für ein bestimmtes Mapping verwendet werden soll. Von der Adressierung ist jedes Vorkommen eines DTM an der gleichen Positionen innerhalb der Datenstrukturdefinition (bzw. Directories) gleich aufgebaut und nicht unterscheidbar.
Daher muss es möglich sein, Elemente präzise ansprechen zu können, wenn es nötig sein sollte.
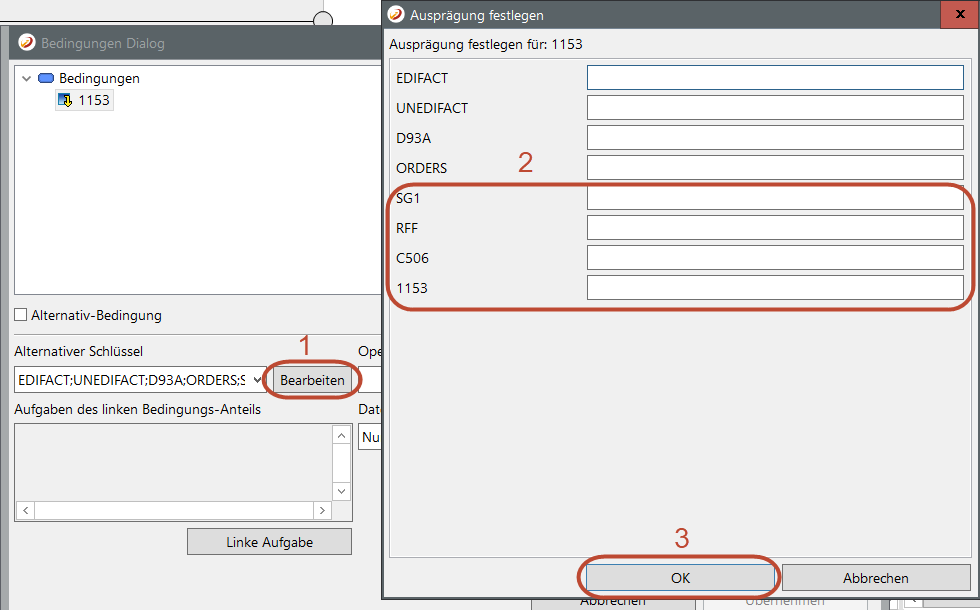
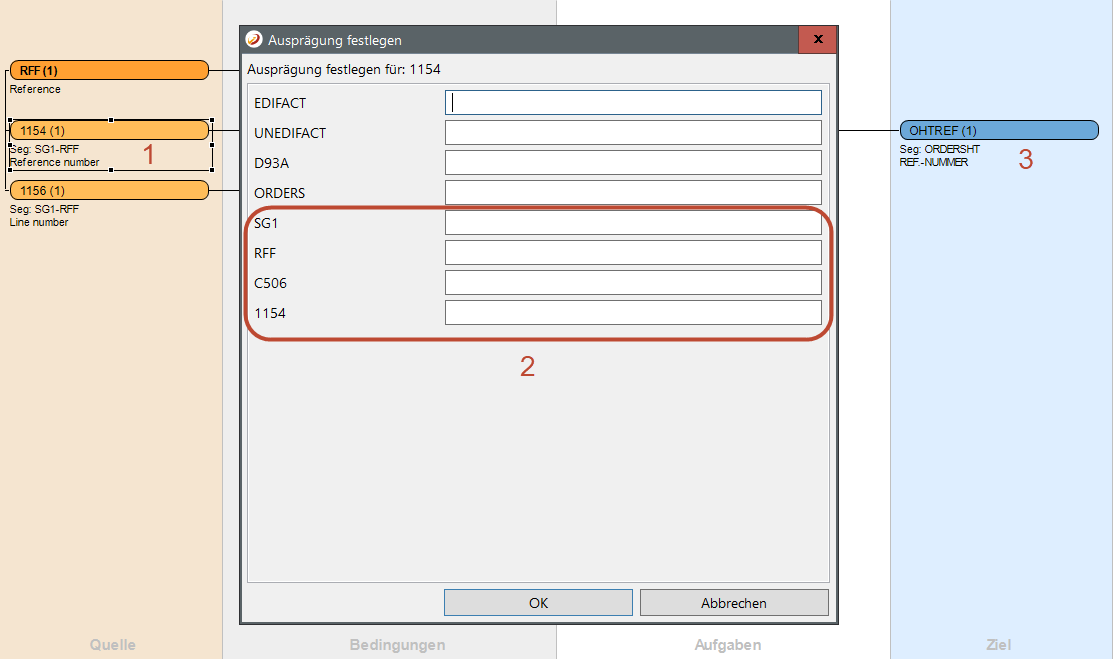
Über einen Doppelklick auf eines der Felder mit 1 bzw. mit Auswahl des entsprechenden Kontextmenüeintrages wird der Dialog geöffnet, mit dem das Vorkommen eines Elements genau spezifiziert werden kann. Der Dialog zeigt alle Schlüsselteile an, die ein Datenelement innerhalb ihres Directories eindeutig festlegen. Für jeden Schlüsselteil kann ein entsprechender Wert für das Vorkommen festgesetzt werden siehe 2. Ein erneutes Öffnen des Dialoges zeigt die bereits eingetragenen Werte an.
Während des Mapping-Prozesses werden auf diese Weise spezifizierte Mappings auch nur mit den passenden Quell-Datenelementen durchgeführt. Gleiches gilt auch für die Schreibrichtung. In diesem Fall dient das Festlegen der Vorkommen dem genauen Platzieren der Zieldaten innerhalb der Ausgangsdatenstruktur.
Occurences bei Bedingungen
Aber nicht nur für die Quell- und Ziel-Elemente können deren Vorkommen spezifiziert werden. Die in Bedingungen verwendeten referentiellen Quell-Elemente können auch spezifiziert werden. Im Bedingungs-Dialog öffnet man eine Bedingung mit referentiellem Wert im Bearbeitungsmodus. Durch Klicken auf 1 wird der Ausprägung festlegen Dialog geöffnet. Je nach Wunsch können die Vorkommen gesetzt 2 und über 3 gespeichert werden.